Sunday-Projects – RSS Analyzer

'Sunday Projects' sind die kleinen, technischen Projekte und Spielereien mit denen ich in unregelmäßigen Abständen meine Zeit verbringe.
Den Auftakt auf diesem Blog macht ein kleines Skript, das die .xml-Datei eines RSS-Feeds (wie zum Beispiel unseren) einliest und die Items, hier nur Podcasts, kategorisiert.
Anschließend wird das Ergebnis, aufgeschlüsselt pro Jahr, in einer Tabelle dargestellt.
Zum Anschauen hier entlang: https://rssanalyzer.org.

Idee
Da Podcast-RSS-Feeds Daten bereits relativ gut strukturiert anbieten, jeder Cast in eigenem <item> Block etc., habe ich mich gefragt, wie man möglichst unkompliziert eine flotte Auswertung dieser hinbekommen kann.
Einfach zu analysieren, sind der Titel, sowie das Datum der Veröffentlichung.
Folgend ein <item>-Beispiel einer Folge des Fundbüros. Die nicht relevanten Informationen habe ich per [...] gekürzt.
<item>
<title>Fundbüro #04 - [...]</title>
<pubDate>Thu, 19 Oct 2023 10:00:00 +0000</pubDate>
<guid isPermaLink="false">[...]</guid>
<itunes:image>
[...]
</itunes:image>
<description>
[...]
</description>
<author>[...]</author>
<itunes:duration>00:46:16</itunes:duration>
<enclosure url="https://m10z.picnotes.de/Fundbuero/Fundbuero_004.mp3"
length="113246208"
type="audio/mpeg"/>
</item>
Die einzelnen Elemente sind überwiegend selbsterklärend. Zwei will ich dennoch kurz erläutern:
guidentspricht der einzigartigen ID dieses Items.enclosurebeschreibt konkret die Dateireferenz dieses Items, hier die entsprechende.mp3-Datei.lengthist die Dateigröße in Byte.
Gehen wir nun davon aus, dass jeder Podcast einer Kategorie zugeordnet werden kann (Fundbüro, M10Z etc.), können wir einfach den kompletten Feed einlesen und alle einzelnen Folgen auf Basis ihres Titels zählen, kategorisieren und in Monate und Jahre unterteilen. Gesammelt und als Tabelle (Screenshot von The Pod, da diese eine interessante Datenbasis besitzen) dargestellt, lässt sich so eine simple Jahresübersicht pro RSS-Feed erstellen.
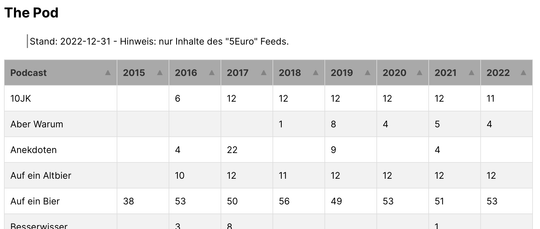
Kein wirklich nötiger Mehrwert, aber eine interessante und kurzweilige Statistik – ich mag sowas.
Zusätzlich konnte ich dafuer mal wieder mein Python Wissen auskramen, viel war da eh nie vorhanden - aber ich mag es durchaus und zu Lernprojekten sage ich selten nein.
Umsetzung
Das Projekt besteht aus zwei Bestandteilen:
- Ein Skript zum Parsen und Katalogisieren von RSS-Feeds
- Python 3.10, xml, yaml
- Transkription per Whisper auf einer RTX 4090
- Eine simple Webseite, die mit den Ergebnissen des Skripts HTML-Tabellen aufbaut
- NextJS, SCSS, Hosting bei Vercel
Im Folgenden erläutere ich den Prozess. Dieser besteht im Wesentlichen aus folgenden Schritten:
- RSS-Feed-Datei (
.xml) beziehen - Diese Datei analysieren
- Mit dem Ergebnis etwas machen – hier in neue Dateien schreiben
- Diese Ergebnisdateien innerhalb der Webseite verwenden und die Daten entsprechend darstellen
Das komplette Skript sprengt den Rahmen dieses Posts, daher nachfolgend die relevanten Ausschnitte.
RSS-Feed laden
Wir laden die Konfigurationsdatei, sowie eine Liste von Dateinamen (die konkreten .xml-Dateien eines Podcasts) und reichen diese weiter.
Dessen Ergebnis (Title / Jahr kategorisierte Items, nicht zuordenbare Items, Alles zur Kontrolle), die fertige Analyse, reichen wir dann zum Speichern weiter.
def create_content(content_path, content_files):
with open(base_path + content_path + '/config.yaml', 'r', encoding='utf8') as file:
content_config_data = yaml.safe_load(file)
title_count_dict, unmapped_titles, full_dict = parse_and_count_titles(
[base_path + content_path + '/' + str(file) for file in content_files],
content_config_data['title-classifier']
)
save_dataframes(content_path, title_count_dict, unmapped_titles, full_dict)
Aktuell müssen die .xml-Dateien des RSS-Feeds lokal im Dateisystem liegen, dies könnte aber sehr einfach automatisiert, bzw. innerhalb des Skripts erst aus dem Internet heruntergeladen werden.
RSS-Feed parsen
Das eigentliche Parsen ist zu viel und zu komplex, um es hier sinnvoll darzustellen, daher hier der Einstieg.
Wir laden jede .xml-Feed-Datei ein und suchen alle <item>-Objekte. Jedes <item> entspricht einem einzelnen Podcast.
Per item.find('title').text können wir dann die gewünschten Daten abgreifen – hier title.
for file in files:
xml_root = get_xml_root(file)
for item in xml_root.iter('item'):
title = item.find('title').text
pub_date = item.find('pubDate')
# [...]
Im weiteren Verlauf wird dann ein Dictionary aufgebaut, in dem wir unsere Podcasts pro Titel und Jahr katalogisieren. Titel werden über die initial geladene Konfigurationsdatei kategorisiert. Hier müssen im Vorfeld alle vorhandenen Podcastformate eingetragen werden. Die Podcastitems, die hier nicht zugeordnet werden können, werden separat in eine extra Ergebnisdatei geschrieben – um anhand dieser die Konfiguration überarbeiten zu können.
Zusätzlich lassen sich auch selbstverständlich nicht alle Podcasts einem jeweiligen Format zuordnen – manche sind entsprechende One-Shots oder Spezialfolgen. Sehr häufig finden sich jedoch auch Tippfehler in den relevanten Metadaten, diese können ebenfalls über die Konfiguration abgefangen werden.
Gerade letzteres würde sich über fuzzy search / mapping, zumindest in vielen Fällen, lösen lassen. Das ist jedoch die Komplexität und den Mehraufwand in diesem Projekt nicht wert.
Ergebnisdateien erstellen
Wir erstellen pandas-DataFrames aus den Python-Dictionaries zur einfacheren, weiteren Verarbeitung.
def save_dataframes(output_base, title_count_dict, unmapped_titles, full_dict):
# Prepare fs directories
output_path = make_directories(base_path, output_base, next_public_path)
dict_dfs = {
'output': prepare_dataframe(title_count_dict),
'unclassified': pd.DataFrame(unmapped_titles, columns=['Unclassified']),
'full': prepare_dataframe(full_dict)
}
for file_type, df in dict_dfs.items():
# Does some preparation and then calls 'write_files'
dataframes_to_files(df, output_path, next_public_path, output_base, file_type)
Wir erstellen die Ergebnisse in drei verschiedenen Dateiformaten und schreiben die Dateien ins lokale Dateisystem.
def write_files(df, output_path, file_type):
file_methods = {
'csv': df.to_csv,
'xlsx': df.to_excel,
'json': df.to_json,
}
for file_ext, method in file_methods.items():
file_path = os.path.join(output_path + dist_path, file_type + '.' + file_ext)
if file_ext == 'json':
method(file_path, orient='index', indent=4, double_precision=0)
else:
method(file_path, index=True)
Audiotranskription
Als Addon habe ich zusätzlich ein kleines Skript erstellt, welches automatisiert .mp3-Dateien transkribieren kann.
Theoretisch ließe sich das ganze recht einfach automatisiert auf sämtliche Podcastdateien innerhalb eines Feeds anwenden.
Ich habe für die Transkriptionen jedoch aktuell noch keinen Anwendungsfall, daher ist dies deaktiviert – der Prozess braucht signifikant Strom und ist nicht zu unterschätzen.
Da die Transkription per KI aus Effizienzgründen auf den CUDA-Cores einer Nvidia-Grafikkarte laufen sollte, ist es wichtig Torch sauber installiert zu haben.
Mit den folgenden drei Zeilen wird dies sichergestellt:
pip uninstall torch
pip cache purge
pip install torch -f https://download.pytorch.org/whl/torch_stable.html
Der Erfolg lässt sich leicht per Taskmanager überprüfen.
- Transkriptionsskript starten
- Im Taskmanager die GPU-Auslastung beobachten
Whisper Script
Das eigentliche Transkriptionsskript ist sehr kurz. Whisper hat quasi die komplette Komplexität gekapselt und stellt sie über eine einfache API zur Verfügung.
import os
import sys
import time
import tqdm
import whisper
# Load the Model
model = whisper.load_model("large-v2")
# Transcribe the .mp3 file
result = model.transcribe('./someAudioFile.mp3', language="German",
fp16=False, verbose=None)
# Write the result to a .txt file
with open('./temp/' + file_name + '.txt', 'w', encoding='utf-8') as f:
f.write(result["text"])
Nach einiger Zeit ist die Transkription fertig und kann aus der .txt-Datei ausgelesen werden.
Die gesamte Audiodatei wird einfach direkt Wort für Wort niedergeschrieben.
Stand heute ist es mit öffentlichen Mitteln noch nicht möglich, SprecherInnen zuzuordnen.
Fortschrittsanzeige
Auf einer aktuellen Nvidia RTX 4090 GPU dauert die Transkription von 60 Minuten .mp3-Material ungefähr zwischen 8 und 12 Minuten.
Um den jeweils aktuellen Fortschritt zu überprüfen, möchten wir diesen idealerweise auf der Kommandozeile ausgeben.
Dazu muss die Standard-Progressbar des Whisper-Moduls überschrieben werden.
class _CustomProgressBar(tqdm.tqdm):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._current = self.n
def update(self, n):
super().update(n)
self._current += n
# Handle progress here
print("Progress: " + str(self._current) + "/" + str(self.total))
Diese können wir dann direkt am Modul registrieren
transcribe_module = sys.modules['whisper.transcribe']
transcribe_module.tqdm.tqdm = _CustomProgressBar
Der Fortschritt der jeweils aktuellen Datei wird dann in der Kommandozeile ausgegeben. Zum Beispiel so:
Progress: 300300/368261.
Beispiel 'En Rogue #1'
Im Folgenden habe ich die Transkription für die Folge En Rogue #1 durchgeführt. Hier die ersten paar Abschnitte:
Herzlich willkommen zu en Rogue, dem unregelmäßigen Podcast zu Rogue-Lite-Likes und was noch so alles dazu gehört. Ich bin Jan und spreche zusammen mit dem Simon. Hallo Welt da draußen. Und dem Adrian. Hallo. Das heißt, wenn ihr das Spiel noch nicht gespielt habt, Podcast ausschalten, Spiel spielen, Podcast wieder einschalten. Wenn ihr schon gespielt habt, dranbleiben. Wenn ihr keinen Bock habt, es zu spielen, dranbleiben. Vielleicht solltest du noch so einen Warnton einbauen. Dieser Podcast wird gespoilert. Okay, ich glaube, jetzt hat jeder Zeit, aufzumachen. Dazu, ich habe das Spiel relativ zügig nach Erscheinen durchgespielt. Oder letztes Jahr? Ich bin mir gar nicht mehr sicher. Ich glaube, letztes Jahr. Und Simon und Adrian habe ich ein bisschen dazu genötigt oder sie auf den Geschmack gebracht, das zu spielen. Das heißt, da sind die Spielerfahrungen etwas frischer. Und ich glaube, wir haben hier auch sehr diverse Wahrnehmungen von dem Spiel, was auch schon mal sehr gut ist. Also ich habe das Spiel sehr, sehr gerne gespielt und war für mich noch im letzten Jahr eins der besten Spiele, die ich in dem Jahr gespielt habe. Wie war denn so eure Erfahrung mit dem Spiel? Ich bringe jetzt mal vor. Also im Großen und Ganzen fand ich es ein hervorragendes Spiel. Das Spiel hat nun, dazu werden wir aber kommen, an einem bestimmten Punkt etwas gemacht, was ich immer noch übel nehme. Und das ist aber auch immer ein gutes Zeichen für ein Spiel, weil es wird mir so auch für ewig in Erinnerung bleiben. Aber halt eben mit diesem kleinen Haken, dass ich es dem Spiel massiv übel nehme, was es da gemacht hat. Und ich es deswegen auch, wenn ich jetzt danach gefragt werden würde, nicht uneingeschränkt empfehlen würde. Wie ist es bei dir, Adrian? [...]
Das komplette Ergebnis als .txt-Datei kann hier heruntergeladen werden.
Ich danke euch fürs Lesen!
Das nächste Sunday Project wird mein physischer Button, der die Windows-HDR-Einstellung an- und ausschaltet. Seid gespannt ;-)
Bis bald. Luca